无
”爬虫 python“ 的搜索结果
早在1989年,网络发明人蒂姆·伯纳斯 - 李(Tim Berners-Lee)就提出了网站的三大支柱:1)URL ,跟踪Web文档的地址系统2)HTTP,一个传输协议,以便在给定URL时查找文档3)HTML, 允许嵌入超链接的文档格式Web的最初...
本文分析了基于Python的新闻聚合系统网络爬虫,指的是根据Python的网络爬虫构建新闻聚合系统,利用爬 虫获取新闻聚合系统的新闻数据,不同网站的页面布局是不同的,因此需要创建开源爬虫,可以在不同页面布局中获取数据。...
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了

爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...
python爬虫python爬虫
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。爬取知乎优质答案,为...
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...

1、python爬取企查查公司信息 2、添加应对反爬的设置 3、开箱即用,有示例数据文件 4、windows版本 5、需要登录或者人工验证 6、采用selenium模块+chromedriver驱动
利用Python来实现的爬虫,高效且可靠。
书籍资源
网络爬虫-Python和数据分析,非常好的python 学习书籍
Python爬虫利器二之Beautiful Soup的用法
爬虫python入门 爬虫python入门实战源码 爬虫python入门实战源码 爬虫python入门实战源码
爬虫python,巨细!Python爬虫详解

讲诉python爬虫的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
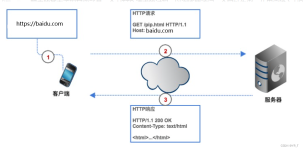
81个Python爬虫源代码
标签: 爬虫
81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础...

基于Python+MongoDB的可配置异步爬虫
该资源为完整版的python代码,python2.7.实现简单的网络爬虫,爬去目标数据
百度贴吧的爬虫制作和糗百的爬虫制作原理...用Python写的百度贴吧的网络爬虫。 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地。 ...
基于Python网络爬虫的设计,可以爬取360新闻,百度贴吧等,百分百可用
对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。
推荐文章
- dotnet run 提示System.Net.Sockets.SocketException (10049): 在其上下文中,该请求的地址无效。...-程序员宅基地
- 一篇文章读懂Kafka消息队列_kafka 2.0.1 poll duration-程序员宅基地
- access连接mysql很慢_怎么解决ACCESS数据库太大造成运行慢的问题?-程序员宅基地
- vue-高德地图-点击地图-获取省市区-获取经纬度-获取街道地址_vue amap.geolocation-程序员宅基地
- WPF-关于动画Animation(及其常见问题)_storyboard doublecollection animation-程序员宅基地
- 利用OpenSSL库对Socket传输进行安全加密(RSA+AES)_aes_set_decrypt_key-程序员宅基地
- 解决虚拟机安装64位系统“此主机支持 Intel VT-x,但 Intel VT-x 处于禁用状态_intel vt-x/ept 要求具备 64 位客户机支持-程序员宅基地
- Linux cpufreq 机制详细解析_eas linux cpufreq-程序员宅基地
- Python获取所有股票代码以及股票历史成交数据分析(二)_stock.csv-程序员宅基地
- LYB-程序员宅基地